OpenAI, 더 이상 모든 ChatGPT 대화 기록 보관 의무 없다.
 QM큐브
QM큐브


- 감사합니다! 08-08
 출석체크
출석체크 질문하기
질문하기



































- 뉴스/정보
-
- 하드웨어 BEST(추천순)
-
- 1 SK하이닉스, 삼성전자 제치고 시총 1위...25년 7개월 만에 역전 28
- 2 수익이 급증하고 있는 두 주요 HDD 제조업체가 생산량 증대를 거부: 내년에는 총마진이 메모리 생산량 증가세에 따라잡을 것으로 예상 21
- 3 AMD 그래픽 카드 가격 인상: 엔비디아의 독점 심화? 15
- 4 RTX 5090의 극심한 열로 인해 고성능 메인보드가 단 6개월 만에 변색되었습니다. 30
- 5 PC 메모리와 SSD 공급 부족 현상 발생: 일부 모델의 가격이 20% 이상 상승 21
- 6 AI發 D램 품귀 현상 DDR2까지 확산⋯3분기도 가격 상승 전망 20
- 7 매일 변동하는 PC 가격, 업체는 과도한 재고를 기피 12
- 8 AMD 차세대 RDNA 5 라데온 GPU, 2027년 중반 출시설 17
- 9 차기 애플 CEO 존 터너스, 퇴색된 디자인 정체성 재정립이 핵심 12
- 10 삼성전자, 오픈AI '챗GPT 엔터프라이즈' 전사 도입…글로벌 최대 규모 9
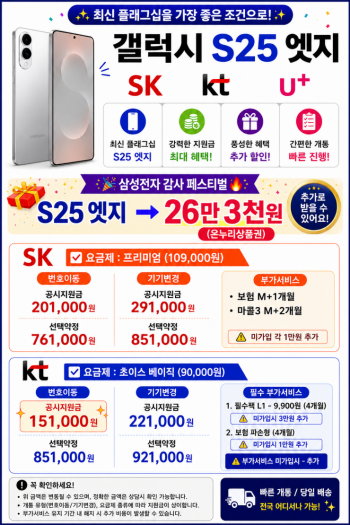
최신 파트너 핫딜1 / 5 820,956원
820,956원
[네이버] 💸넾다세일💸LG전자 OLED 게이밍모니터 27... 4
 38,900~원
38,900~원
[네이버] 에어르 슬릭/베놈/더그램 무선청소기 3종... 4
 0원
0원
[기타] 🚨SK유심단독 번호이동 특가🚨 월 33,000원... 5
 38,000원
38,000원
[네이버] 온랩 혈행 중성지방 콜레스테롤 개선 홍국트리오... 4
 277,000원
277,000원
[네이버] 듀얼모터 모션데스크 MD303D 27만원대! ... 4
 0원
0원
[기타] 💥 A17 공짜+현금 최대 25만 / 퀀텀6 공... 4
 21,990원
21,990원
[지마켓] 인기 이온음료 240ml x 5종 6개씩 총 ... 4
 423,195원
423,195원
[지마켓] 빡세일_연장 LG 게이밍모니터 27G640A ... 4
 247,624원
247,624원
[지마켓] 빡세일🎊 LG 32인치게이밍모니터 32G600... 4
 148,000원
148,000원
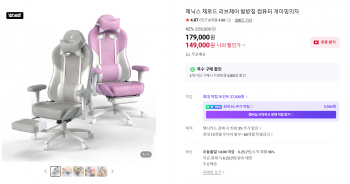
[네이버] 에이픽스 인기 발받침 의자 GC201FR 넾다... 4
 198,000원
198,000원
[네이버] 신제품 코너핏데스크 출시 특가! ㄱ자 책상 1... 4
 145,116원
145,116원
[네이버] 넾다세일 스타트! LG 모니터 가성비 게이밍부... 4
최신 공식 기사1 / 3